
在日常交谈中,相互注视和摆动头部等动作都是自然对话的组成部分,尤其是当我们在面对面交流中变换话题、控制发言或转换交流对象时,都会伴随眼神和肢体动作的交流。然而,当前的视频会议技术却存在着一定的缺陷——由于摄像头和屏幕不在同一高度,如果看向屏幕眼神往往很不自然,如果看向摄像头则无法关注到其他与会者的反应,因此视频会议缺少了线下交流的真实感和互动感。而且在实际的工作中,我们还会有各种不同的会议场景,比如多人会议、同排而坐协同工作等情况,对于捕捉与会者的侧方视线和动作来说,现有的视频会议系统就更无能为力了。
如果有一个会议系统,可以让人们即使身处不同的地方,也能像在同一房间里一样交流,视线转动就能与同伴建立起眼神沟通,这是否会给远程办公增添一份沉浸式的真实感呢?

利用现有的普通硬件设备搭建的 3D 视频系统

VirtualCube 系统具有三大优势:
标准化、简单化,全部使用现有的普通硬件设备。与办公场所中常见的格子间(Cubicle)类似,每个 VirtualCube 都提供了一致的物理环境和设备配置:与会者正前方安装有6个 Azure Kinect RGBD 摄像头,以捕捉真人的图像和眼神等动作;在与会者的正面和左右两侧还各有一个大尺寸的显示屏,以创造出身临其境的参会感。使用现有的、标准化的硬件能够大大简化用户设备校准的工作量,从而实现 3D 视频系统的快速部署和应用。

6个 Azure Kinect RGBD 摄像头捕捉人像和眼神等动作
多人、多场景,任意组合。作为在线视频会议的基础构建,VirtualCube 的虚拟会议环境可由多个空间(Cube)按照不同的布局组成,以支持不同的会议场景,例如两人的面对面会议、两人并排会议,以及多人的圆桌会议等。
多个空间(Cube)可实现任意组合
实时、高质量渲染真人图像。VirtualCube 可以捕捉到参与者的各种细微变化,包括人的皮肤颜色、纹理,面部或衣服上的反射光泽等,并实时渲染生成真人大小的 3D 形象,显示在远程与会者的屏幕中。而且虚拟会议环境的背景也可以根据用户的需求自由选择。

任意变换会议场景,都能身临其境
V-Cube View和V-Cube Assembly算法双剑合璧,沉浸式会议体验不再是难题
其实业界对 3D 视频会议的研究从未间断过。早在2000年,就有人曾提出过与类似混合现实技术有关的畅想。基于这个设想,科研人员一直在探索如何将视频会议以更逼真、更自然的方式呈现,期间也出现了不同的技术路线和解决方案,但都没有达到理想的效果。对此,微软亚洲研究院主管研究员张译中和杨蛟龙表示,过往的研究仍然有很多没有解决的问题:首先,在真实环境下,无论放置怎样的单目摄像设备,即使图像质量再高,与会者也很难形成自然的眼神交流,特别是多人会议的情况;其次,很多研究针对特定的会议场景进行优化,如两个人面对面的会议或三人的圆桌会议,很难支持不同的会议设置;第三,虽然在影视界我们能够看到一些逼真的虚拟人,但那是需要专业的技术和影视团队长时间打磨和优化才能实现的,仍然需要一定的手工劳动,目前无法进行实时捕捉和实时渲染。
为此,微软亚洲研究院提出了 V-Cube View 和 V-Cube Assembly 两大全新算法,在 VirtualCube 中实现了自动捕捉参与者的手势动作和眼神变化,实时渲染形成高保真图像,让参与者在虚拟会议中体验到真实会议的氛围。

“两个人在交谈且相互注视对方时,对方看到的自己就相当于在自己眼睛的位置放置一个摄像头。但屏幕和摄像头的位置存在高低差,所以当一方注视屏幕中对方的眼睛时,摄像头捕捉到的眼神就会偏离。因此在 VirtualCube 中,我们在与会者正前方的屏幕边缘放置了六个摄像头,通过 V-Cube View 算法合成正确的视点图像,并利用 V-Cube Assembly 确定正确的相对位置,进而给与会者一个沉浸式的会议体验”,张译中介绍道。
基于深度学习的 V-Cube View 算法,通过 VirtualCube 中的六个摄像头的 RGBD 图像作为输入,实时渲染任意目标视点下人的高保真视频。这里的技术挑战是如何同时做到高保真和实时。对此,微软亚洲研究院主管研究员杨蛟龙解释道:“实时渲染高保真的人像,特别是高保真的人脸一直是个具有挑战性的研究课题。传统的三维重建和纹理贴图的做法虽然可以做到实时绘制,却无法重现出真实人脸复杂的材质和在不同视点下外观的变化。为此我们提出了一种新的 Lumi-Net 渲染方法,其核心思想是利用重构的三维几何作为参考来实现一个四维光场的实时渲染,并结合神经网络进行图像增强,从而提高了渲染的质量,特别是人脸区域的高保真度。”
具体而言,V-Cube View 算法分为三步进行。首先,研究员设计了一个神经网络来快速求解目标视点深度图作为人体的几何参考(geometry proxy)。然后,算法在给定的几何参考下将获取的多视角 RGB 图像(即光线)进行融合,实现绘制。在这一步中,研究员受传统的非结构化流明图(Unstructured Lumigraph)方法启发,将输入光线与目标像素光线的方向和深度差异作为先验,通过神经网络学习最合适的融合权重。最后,为了进一步提升绘制质量,研究员们使用了神经网络对上一步的绘制结果进行图像增强。整个算法实现了端到端的训练,并在训练过程中引入了感知损失函数及对抗学习技术,使得算法可以自动学习出最优的神经网络,实现高保真的绘制。而且为了保证绘制的实时性,算法的前两步都在低分辨率图像上执行,这样可以在不损失太多精度的情况下大大降低所需计算量。经过精心设计和优化的 V-Cube View 算法,将实时的三维人物渲染质量提升到了一个新的高度。
V-Cube View 算法示意图
另外,为了让 VirtualCube 的使用者拥有和线下交流同样的体验,在将与会者映射到虚拟环境时,系统还要考虑他们之间的相对位置关系,这时 V-Cube Assembly 算法就发挥了重要的作用。“在整个虚拟会议环境中,V-Cube Assembly 可以被定义为全局坐标系统,单个的 VirtualCube 则为局部坐标系统。全局坐标系与局部坐标系之间的正确 3D 几何变化,对在视频显示器上正确呈现远程与会者的图像至关重要”杨蛟龙介绍。
研究员们首先会在 VirtualCube 中捕捉与会者的 3D 几何体,形成局部坐标系,然后将这些局部坐标系的 3D 几何体数据,投射到全局坐标系,经过 V-Cube Assembly 处理,在全局虚拟会议环境中确定每个 VirtualCube 参与者正确的相对位置,最后再将全局 3D 几何体转换为 VirtualCube 的局部坐标系,影射到 VirtualCube 的屏幕上。
V-Cube Assembly 算法示意图
抛砖引玉,畅想未来办公无限可能
VirtualCube 给 3D 视频会议系统提供了一种全新的思路。无论从算法设计、端到端设备部署还是工程调试上,VirtualCube 都证明了利用现有的普通硬件设备就可以实现沉浸式的 3D 视频会议体验。
除了让与会者“共享”同一个物理空间外,研究员们还在探索利用 VirtualCube 系统满足远程办公中的更多协作需求。例如,研究员们展示了这样一种场景:在协同工作时,两位与会者及其电脑桌面都将是视频会议的一部分,因此与会者并排而坐,并且跨屏幕传递自己桌面上的文档和应用程序会让远程协作更加方便。
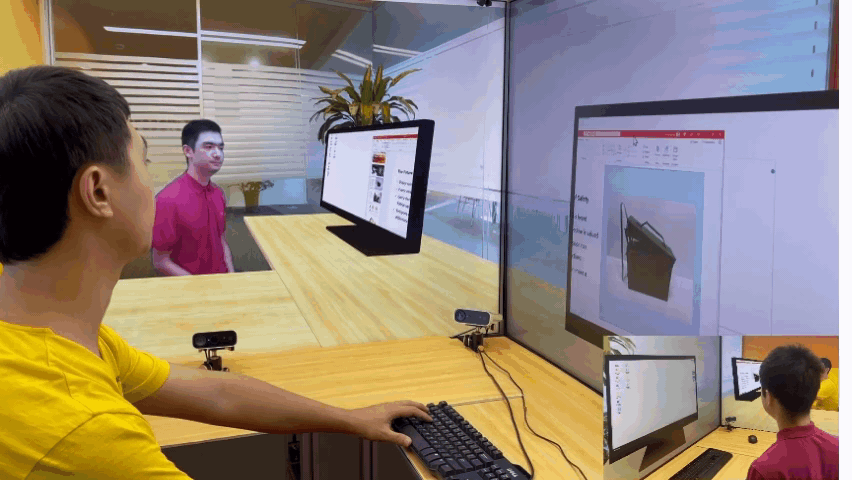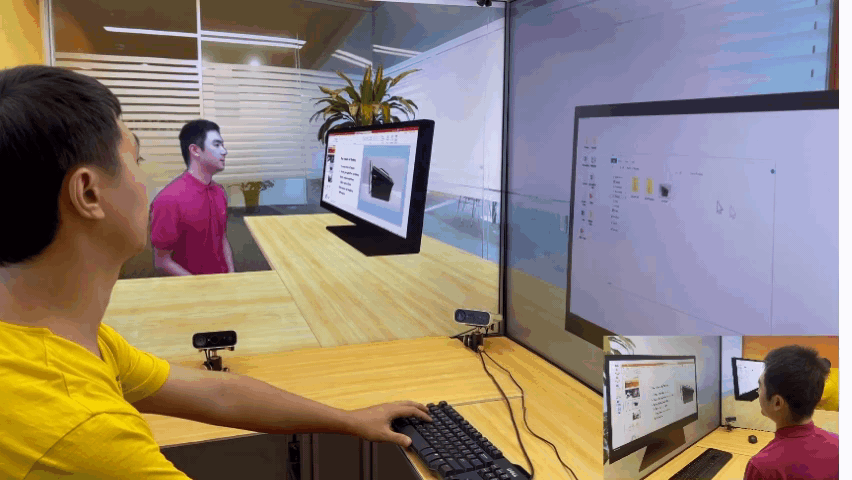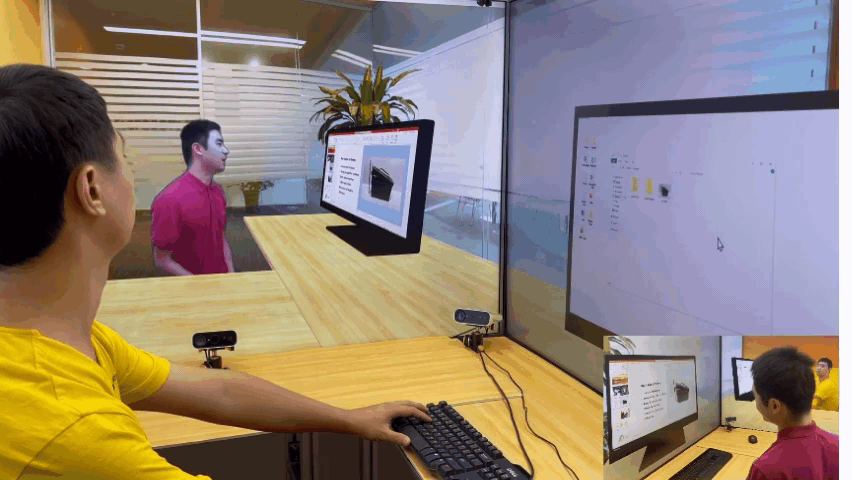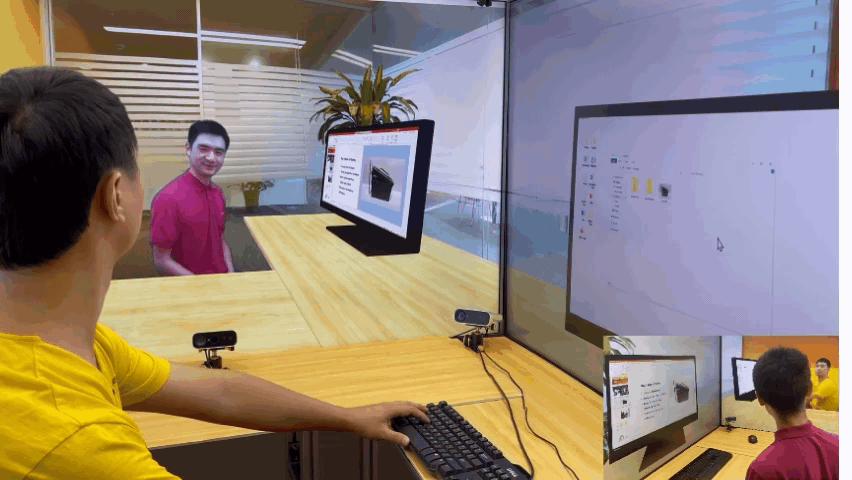
随着技术的不断精进,未来,大家或许都可以实现身隔万里,却能亲临其境一起办公,自然沟通的遥在体验,而这将极大地提高混合办公的效率。微软亚洲研究院的研究员们也希望 VirtualCube 可以成为一颗探索的种子,给更多研究人员带来启发,在大家共同的努力下,找到更好的虚拟空间交互形式,打开未来办公的更多可能。
来源:微软亚洲研究院
投稿:tougao@arinchina.com
稿件/商务合作: Vicky(微信 ARC-vicky)
创始人:张明军(微信 13720775110)
更多精彩内容,请关注ARinChina微信公众号(ID:X增强现实)



评论