
从游戏到电影,再到虚拟现实和混合现实,市场对新的视觉3D内容需求正不断增长。在名为《SNeRF: Stylized Neural Implicit Representations for 3D Scenes》的论文中,Meta提出了一种有趣的方案:用毕加索或莫内等艺术家的美术风格视图来渲染3D世界,并允许穿戴VR头显的我们在其中漫步探索。

直接将基于图像的样式化技术应用于3D场景会导致不同视图之间出现闪烁伪影,因为每个视图都是独立样式化,没考虑底层3D结构。尽管社区已经探索了各种3D表示方法来解决这个问题,但大多不能很好地捕捉目标样式,因为它们只对场景的外观进行样式化,而几何同样是样式的重要组成部分。
最近,神经辐射场(NeRF)提供了一种可以产生高质量新视图合成结果的紧凑3D场景表示。紧凑性、表现力和灵活性令NeRF成为一种极具吸引力的选择。然而,采用NeRF进行神经风格转换会带来巨大的内存约束。要从NeRF渲染像素,必须沿camera光线进行密集采样。这需要大量内存用于渲染和执行反向传播。
针对这个问题,Meta提出结合神经负反馈和基于图像的神经风格转换来执行三维场景样式化。神经风格转换实现了一种灵活的样式化方法,不需要专业美术的示例输入。另外,研究人员通过将3D场景样式转换过程分为两个交替运行的步骤来解决NeRF的内存限制。这允许他们能够充分利用硬件的内存容量,在高分辨率图像渲染NeRF或执行神经风格的传输。
在在《SNeRF: Stylized Neural Implicit Representations for 3D Scenes》这项研究中,他们重点研究了样式化三维场景以匹配参考样式图像的问题,并提出了一种三维场景神经样式化框架SNeRF。据介绍,它可以生成样式化三维场景的新视图,同时保持交叉视图的一致性。
具体来说,给定一个三维场景,团队的目标是对其进行操作,并令所述场景的渲染图像与参考图像的样式相匹配。另外,来自不同视图的同一场景渲染图像应保持一致。所以,由于紧凑性和灵活性优势,研究人员使用NeRF作为场景表示的选择。他们提出了一种内存高效的训练方法,可以在样式化和NeRF训练之间交替进行,从而获得高分辨率的结果。
Meta使用以下函数对表示为NeRF的3D场景进行样式化,从而匹配参考样式图像:
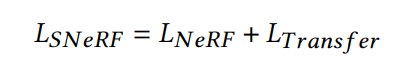
之前社区的研究是同时优化了两种损失,以进行场景样式化。这需要从NeRF渲染完整图像,从而在每个训练步骤计算𝐿tran𝑠fer。这非常耗时。另外,这种方法需要在三个内存密集型组件之间共享内存,大大限制了样式化结果的分辨率以及样式化方法的选择。
为了解决上述方法的内存负担,团队提出了一种受坐标下降启发的交替训练机制。他们的见解是,可以解耦𝐿tran𝑠fer和𝐿nerf , 一次最小化一个。计算𝐿tran𝑠fer,只需要特征提取器、目标样式图像和场景的渲染图像。同时,要计算𝐿nerf,只需要体三维渲染器和目标图像。

所提出的交替训练机制允许将全部硬件容量用于图像样式化或NeRF训练。对于图像样式化,这使他们能够对整个图像执行样式化,并实现更全局一致的样式化结果。对于NeRF训练,可以训练NeRF以生成更高分辨率的结果,并将所属方法应用于动态场景。使用相同的硬件,所述训练机制现在可以将NeRF样式化,并合成1008×756大小的图像。这比以前同时进行训练和样式化时所能合成的图像大4倍。
为了展示样式化方法的灵活性,团队在3种不同的场景类型训练SNeRF:室内场景、室外场景和动态Avatar。对于室内场景,他们使用LLFF数据集中的场景Fern和TRex训练NeRF。对于室外场景,使用来自坦克和寺庙数据集的场景卡车、火车、M60和操场来训练NeRF++。他们同时使用所述方法来样式化4D Avatar。
对于NeRF场景,使用大小为1008×756的图像对3D场景进行样式化。对于NeRF++,使用卡车980×546、火车982×546、M60 1077×546和操场1008×548的图像。对于动态4D Avatar,使用大小为512×512的图像进行训练。




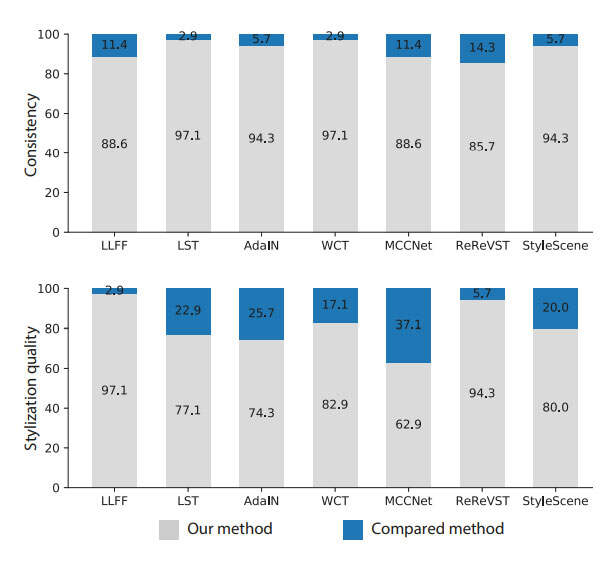

如上图所示,与图像和视频风格传输方法相比,他们定性和定量地展示了SNeRF在生成多视图一致性结果方面的优势。实验同时表明,与其他基于3D的方法相比,Meta的方法产生了更好的样式化结果,这主要归因于相关方法在样式化3D场景几何体和外观方面的灵活性。
与专注于静态场景的现有方法不同,团队的方法同时可以将动态内容样式化,例如4D Avatar。研究人员观察到,样式化结果的质量部分取决于使用RGB图像训练的场景函数的质量。例如,在图8中,与ground truth RGB图像相比,底层NeRF模型无法捕捉背景中植被的清晰细节。这最终会导致模糊的样式化结果。
请注意,即使使用Meta方法训练样式化NeRF需要一定的时间,但一旦训练完成,它们就可以“烘焙”用于AR、VR和MR应用中的实时渲染。除了RGB图像,未来的研究可以探索使用额外的分割或深度图进行样式化。
当然,团队坦承当前的方法存在不足的地方。例如,他们目前独立地对每个场景进行样式化,在不重新启动优化过程的情况下,无法对每个场景应用任意样式。因此,将框架与最近关于任意风格转换的研究相结合将是一个有趣的方向。
来源:映维网
投稿:tougao@arinchina.com
稿件/商务合作: Vicky(微信 ARC-vicky)电话:18700987744
创始人:张明军(微信 13720775110)
更多精彩内容,请关注ARinChina微信公众号(ID:X增强现实)



评论