
为3D骨骼角色创建逼真人体运动是AR/VR等图形应用的重要过程之一。Motion in-betweening是创建骨骼动画的一种流行方法:美术提供时间粒度较小的关键帧姿势,而系统可以自动生成粒度更精细细的中间姿势。当关键帧姿态在时间上足够接近时,简单的线性或样条插值可以产生平滑和合理的结果。但由于约束不足,随着它们变得越来越稀疏,插值就变得不再简单。
业界有人提出了稀疏关键帧姿势(例如超过1秒)的Motion in-betweening方法,通过使用现有的运动数据集并以有监督方式学习深度神经网络。一旦学习了模型,生成的中间姿态将属于训练数据的分布范围,如果使用足够大和高质量的数据,则有可能解决约束不足和自然度问题。
在《Motion In-betweening for Physically Simulated Characters》的论文中,Meta人工智能团队和韩国首尔大学展示了一种新方法来解决稀疏关键帧姿势的Motion in-betweening问题。
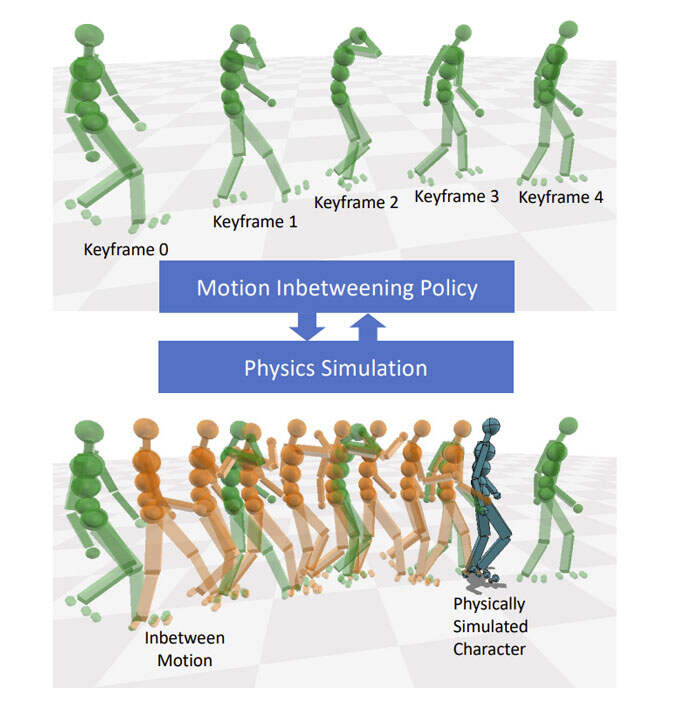
具体地说,团队基于物理模拟的character生成中间姿态,并使用深度强化学习(RL)来训练控制policy。他们开发了适用于所述问题的新公式,其中状态只能访问稀疏的输入姿势,而reward则是根据ground truth运动计算。
由于所述方法使用物理模拟的character,因此与现有的基于运动学的方法相比,它具有多个独特的优势。例如,即便给出了糟糕的输入姿势,它都可以产生物理上合理的运动。
研究人员的系统采用一系列关键帧姿势P关键帧 和固定的粗略时间间隔作为输入,然后以所需的密集时间间隔输出运动。他们的目标是生成平滑、符合物理、看起来自然的运动,并合理地满足输入关键帧约束。
更具体地说,框架学习了一种基于深度强化学习(RL)的模仿policy。RL中的state包括关键帧state和模拟state。RL中的action是stable PD control的目标姿态,它计算关节力矩来启动模拟character。物理模拟然后计算下一个状态。
研究人员使用了multiplicative reward function,通过关节角度、关节速度、末端执行器位置、质心位置和根关节变换这五个不同项来测量模拟运动和ground truth运动之间的相似性。
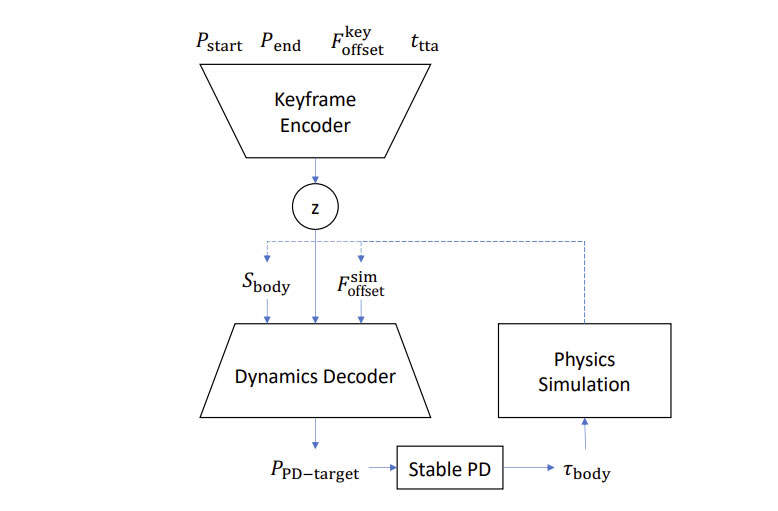
图2描述了在控制策略中采用的编码器-解码器结构。这里的想法是使用关键帧编码器来生成当前时间步长的中间姿势的简化向量表示z。编码器的输出与模拟状态连接,并馈送到动态解码器以产生动作。
团队采用了ScaDiver的开源实现来部署所述方法。PyBullet和RLlib分别用于物理模拟和深度强化学习,近端策略优化则用作深度RL算法。他们在两种类型的运动上独立训练了模型:来自LaFAN1数据集的11个运动序列(≈45.5分钟);使用预训练的PFNN controler随机生成的10个行走序列(≈10分钟)。
训练总共需要大约3天,并大约生成了400M个模拟步长。图1显示了生成的中间姿势的快照。模型用LaFAN1数据集训练,其中学习的控制策略可以成功匹配输入稀疏关键帧,并同时生成物理上合理且类似于地面实况运动的运动。
为了比较方法的有效性,团队用与上述相同的数据训练了一个基线模仿策略,而这个策略消耗了密集指定的关键帧姿势(即未来的参考运动)。由于所述信息在测试期间不可用,他们通过线性插值输入的稀疏关键帧姿势来提供伪参考运动。
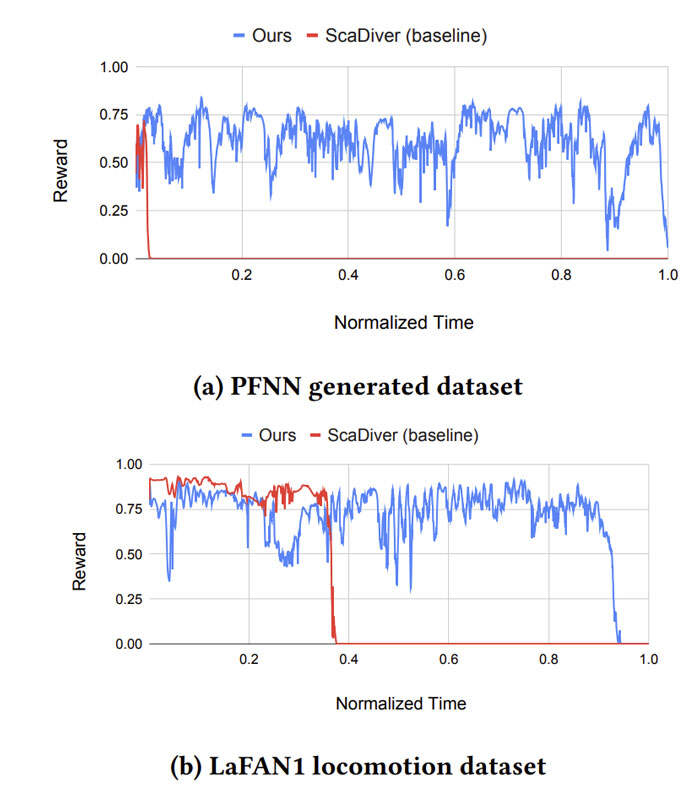
图3显示了性能比较,其中reward值是沿着归一化时间描述。Meta和韩国首尔大学团队的策略在很大程度上优于基线策略,因为基线存在训练/测试时间之间的state不匹配。
来源:映维网
投稿:tougao@arinchina.com
稿件/商务合作: 向前(微信 Shixiangqian7)电话:18700987744
创始人:张明军(微信 13720775110)
更多精彩内容,请关注ARinChina微信公众号(ID:X增强现实)



评论