
XR技术在娱乐、通信、广告、教育、医疗保健、国防、机器人、智能制造、人机交互等领域有着广泛的应用。随着XR应用程序的计算密集度越来越高,这对设计便携式XR设备和系统提出了新的挑战。由于本地设备的功率,计算能力和内存容量的限制,当前一代的便携式XR设备依赖于高性能计算服务器来执行繁重的计算。然而,这种方法存在缺点,包括不完整和不无缝的用户体验,数据传输/网络开销,以及用户隐私和安全问题。
在XR领域内,国内也有众多成功案例,以塔普翊海为例,塔普翊海(RealMax)是一家XR解决方案全球供应商,具备从元宇宙内容、应用开发到智能终端的技术和业务闭环能力,致力于为各行业打造沉浸式无边界、全可视化、多场景、多人交互的智能场景应用,让XR技术为产业提供更多动能。“REALMAX 乾”作为119.5°大可视角沉浸式的AR眼镜一体机,搭载自主研发双自由曲面光学系统和六自由度空间定位图片定位,采用RGB摄像头、双鱼眼摄像头,可实现多样化场景任意互动。

计算机视觉深度学习等技术的爆炸性增长令基于计算密集型人工智能的技术成为未来XR系统的自然用例。
在名为《Memory-Oriented Design-Space Exploration of Edge-AI Hardware for XR Applications》的论文中,Meta和印度理工学院的研究人员进行了详细的架构设计空间探索和设计技术协同优化,以提升便携式XR系统。
团队主要分析了两种XR特定的计算机视觉人工智能工作负载,在三种架构进行XR-AI应用程序的基准测试,并对所有三种架构在28nm、22nm和7nm的工艺节点进行了技术可扩展性研究,并研究了它们各自的EDP趋势。
研究结果表明,当在存储器层次结构中引入MRAM NVM时,手部检测(在IPS=10时)和眼睛分割(在IPS=0.1时)分别观察到≥24%的存储器能量节省。另外,由于MRAM技术的高密度特性,MRAM取代SRAM可大幅减少面积(≥30%)。
不过,根据工作负载的性质和应用程序的IPS要求,用NVM完全替换板载易失性存储器可能不是最佳选择,因为NVM写入延迟可能会限制计算速度。另外,考虑到最先进的NVM设备的读写操作的非对称能量耗散趋势,功率效益可能会受到限制。因此,基于工作负载的确切性质(即以存储器读取为主或以存储器写入为主),需要仔细微调NVM和SRAM之间的拆分比例,从而获得最佳结果。
分析代表性的XR-AI负载
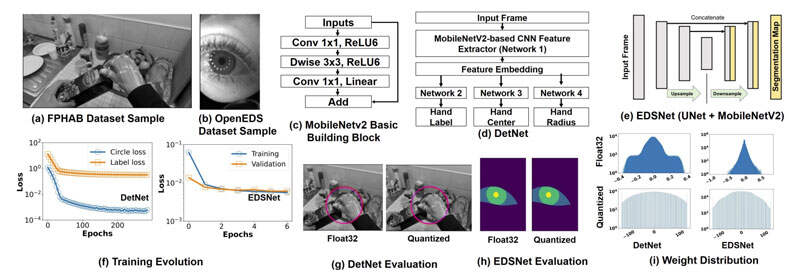
研究人员提出了XR-AI推理工作负载中使用的网络的算法方法,随后给出了关于基于量化的推理优化的细节。手部检测和眼睛分割已大量用于VR和AR头显。
瞳孔、虹膜、巩膜等眼部生物特征的分割已广泛用于研究眼球运动和进行注视点估计。同样,一系列的头显已经采用了基于视觉的手部追踪,并将其作为XR设备的一种方便且低摩擦的输入。因此,这两个应用程序都是在XR-AI的各种计算平台进行基准测试的代表。
实现
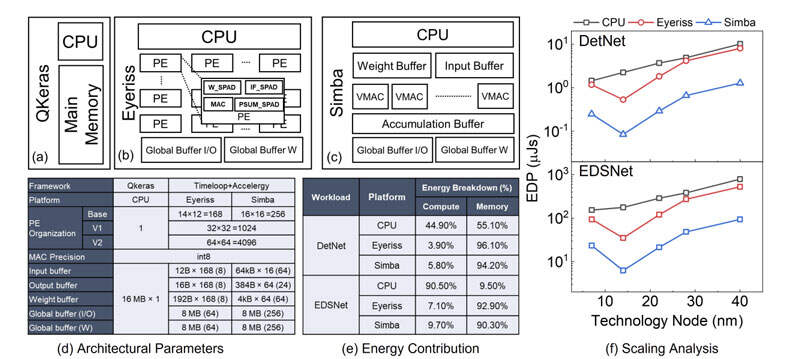
如图2所示,团队在三种模拟架构对XR-AI工作负载进行了基准测试:
(i)一个通用CPU和两个收缩推断加速器
(ii)Eyeriss
(iii)Simba
所述架构模拟有助于研究各种重要设计参数的作用,如数据路径、操作映射、并行性和内存层次结构。
Eyeriss和Simba的主要区别在于的内存组织。尽管Eyeriss在很大程度上依赖于每个PE(处理元件)的本地化内存,但Simba以输入缓冲区、权重缓冲区和累积缓冲区的形式跨行使用共享缓冲区。
对于架构工作负载映射和网络模拟,研究人员使用了以下三个框架:QKeras、Timeloop和Accelergy。在QKeras(CPU)的情况下,他们首先将模型转换为Keras,然后使用QKeras库进行量化,并基于到CPU指令集的操作映射进行能量估计。
QKeras将工作负载映射到纯CPU架构,并提供45nm节点的能量估计。QKeras同时允许选择存储器配置:(a)SRAM-only;(b)SRAM+DRAM with writeback;(c)DRAM-only。
对于当前的研究,团队对存储器使用SRAM-olny的配置。Timeloop用于估计两种神经网络工作负载在基于Eyeriss和Simba的收缩PE的循环操作映射。对于使用Timeloop,他们通过pytorch2timeloop转换器从torch导出模型。然后,对基线Simba和Eyeriss进行了以下修改,使其与XR-AI用例更加相关。
首先,将DRAM从两个加速器中完全移除,并根据图2(d)所示的工作负载要求选择SRAM全局缓冲区大小。尽管SRAM和DRAM都是易失性存储器技术,但DRAM提供了较低的面积/成本,而SRAM提供了对此类应用至关重要的延迟和能量优势。
其次,使用Aladdin的40nm标准单元库作为参考,以取代Accelergy提供的原始45nm单元库。40nm的能源库的采用使INT8能够支持Eyeriss,而不是默认的INT16 MAC操作。另外,由于40nm库在加法器/乘法器/寄存器中提供了多个版本的模块,所以它在能量延迟权衡的基础上通过Accelergy实现了DTCO。
如图2(b)和(c)所示,CACTI用于估计各种SRAM缓冲器的能量。用于推断工作负载手检测和眼睛分割的估计EDP如第2(f)所示。
同时,研究人员预测了所有三种架构的更先进节点(28nm、22nm和7nm)的能量缩放。。从基线技术节点(CPU为45nm,Simba/Eyeriss为40nm)进行扩展,可使所有架构的能耗降低4.5倍。尽管收缩加速器可能在延迟方面具有显著的好处,但可以观察到,与基线CPU相比,能量成本显著增加。
Simba显示,DetNet和EDSNet分别节省了26%和33%。在7nm的情况下,Simba和Eyeriss对EDSNet显示出类似的能量耗散,而在DetNet的情况下Simba显示出相较于Eyeris节能11%。EDSNet在7nm处观察到的差异可归因于工作负载的内存密集性质。
基于NVM的优化
前面探讨了网络架构和计算平台在EDP方面的含义。除了图中所示的绝对能量外,图2(f)、图2(e)进一步分析了收缩结构(Eyeriss和Simba)的能量耗散,并表明内存功耗远比计算功耗重要,并为优化留下了更多空间。
从以往的研究中可以明显看出,特定XR-AI工作负载在其时间计算需求方面高度不对称,亦即AI计算可能不会在每个周期执行,同时不会随着时间的推移而一致执行,而是以零星的方式执行。这种特殊的计算需求可以受益于边缘AI加速器的主动功率门控(例如常关计算),以延长电续航。
实现电源门控边缘系统所需的一个重要组件是NVM。NVM能够从关闭/睡眠模式快速唤醒,而无需将耗电且耗时的数据重新加载到SRAM或主存储器。由于使用了额外的BEOL工艺或3D集成,可以观察到NVM的主要优点。
与高密度SRAM相比,SOT-、VGSOT-和STT-MRAM可以实现高达1.3x、2.3x和2.5x的单元面积减少。另外,新兴磁阻/自旋电子NVM的最新进展已使器件性能与SRAM相当。为了评估这一前景,研究人员在XR-AI计算管道中包括了两个最先进的NVM设备STT和SOT后,对两个XR-AI工作负载的上述架构的能量耗散进行了详细分析。
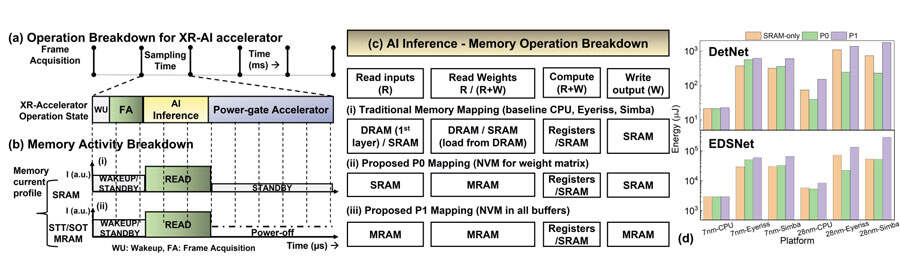
模拟XR-AI管道的时间运行周期如图第3(a)所示。它涉及以下顺序的执行模式:
(i)加速器唤醒(WU)
(ii)帧获取或帧加载(FA)
(iii)AI推断,以及(iv)加速器的功率门控。
系统中使用的存储器类型(SRAM或NVM)将对整体延迟和能量产生直接影响。仅使用易失性SRAM的管道将遵循图3(b)-(i)中所示的操作周期,而使用图3(b)-(ii)中NVM的备用管道可以在执行推理后的间隔期间断电,而无需任何重写。
由于内存的非波动性,可以选择关闭电源模式,从而节省能源。团队提出了两种策略,P0和P1映射,如图第3(c)所示,在XR-AI工作负载的边缘设备中采用基于NVM的管道。人工智能推理的每个推理周期内存操作分解如图第3(c)所示。
在图3(c)-(ii)所示的所提出的P0映射中,研究人员仅针对权重存储器引入NVM(STT和SOT)。在更激进的变体P1映射中,他们用NVM替换所有SRAM存储器缓冲器,如第3(c)-(iii)所示。
结果和讨论
为了估计所提出的变体P0和P1的能量,团队使用了MRAM和SRAM宏观能量表征,以及他们的计算/MAC能量分析,通过使用基于Timeloop+Accelergy和QKeras模拟的操作计数来估计总工作负载能量。
CPU采用64位内存位宽,而Timeloop采用特定于体系结构的内存位宽。图3(d)对两个技术节点(28nm和7nm)的九种不同模拟架构变体(CPU、Eyeriss和Simba各有三种风格)的两种XR-AI工作负载的能量趋势进行了全面分析。
对于三种架构中的每一种,团队都考虑了三种存储器类型:SRAM-only、P0:SRAM+MRAM和P1:MRAM。用于7nm估计的NVM技术是VGSOT-MRAM[,而不是STT-MRAM。由于用于VGSOT-MRAM的参数是基于高度缩放的器件所估计,因此采用了基于缩放因子的方法来首先根据SRAM进行能量缩放。随后是SRAM到VGSOT-MRAM。能量分析的关键观察结果如下所示:
- 与SRAM-only的情况相比,对于7nm,P0和P1变体在收缩加速器方面显示出更高的能量耗散,而对于CPU,无论工作负载如何,能量耗散几乎相等。
- P1变体显示了跨两个节点的所有架构和工作负载的更高能量耗散。原因是与SRAM相比,MRAM显示的读写操作的能量不对称。在28nm,所有架构的P0变体与两种工作负载的SRAM-only情况相比都显示出能耗节约,而在7nm处则存在相反的趋势。这可归因于STT-MRAM和VGSOT-MRAM所证明的读取能量成本的差异,即VGSOT-MRAM优化用于写入,而STT-MRAM被优化用于读取。
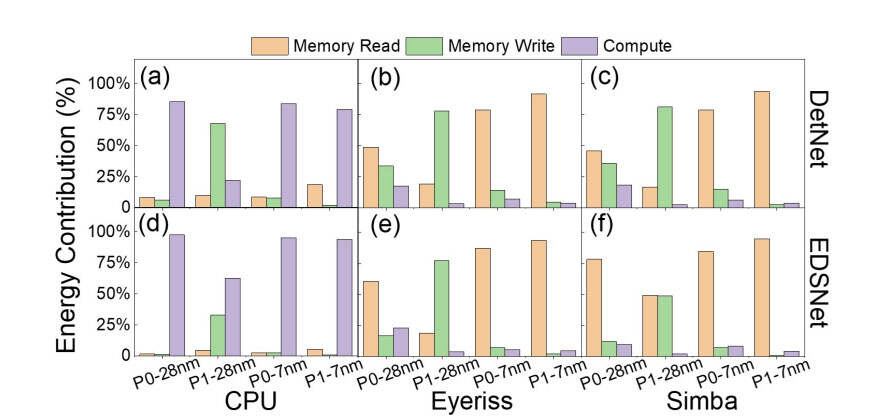
计算和内存操作(读/写)方面的详细能量分解如图4所示。计算能量在CPU的内存中占主导地位,两种收缩加速器的趋势都相反。这可以归因于CPU采用的顺序计算数据流,从而减少了不必要的内存获取。对于P1-7nm,与所有架构和工作负载的存储器写入能量相比,存储器读取能量变得压倒性地占主导地位(≈50倍)。这可以归因于,用于7nm的VGSOT器件在写入方面更优化。
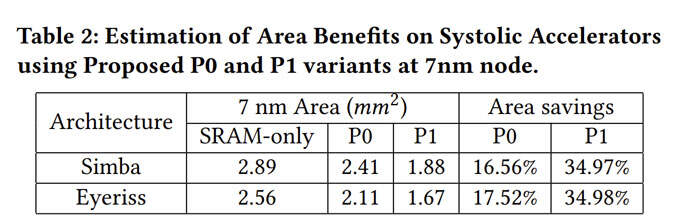
接下来,研究人员通过在7nm节点引入用于收缩加速器架构的NVM来分析面积方面的优势,并得出了P0和P1变体的面积估计值,如表2所示。尽管P0变体在面积上显示出边际效益(≈2%),但与标准的仅SRAM架构相比,P1变体显示出34%的面积节约。对于P0变体的较小面积优势,一个关键原因可以归因于小内存宏的外围区域开销。然而,对于涉及视频流的更复杂的工作负载,权重内存可能会成为一个重要因素,P0可以实现更好的节约。

图5(a-d)和图5(e-h)分别显示了P1和P0变体的存储器能量节省结果。
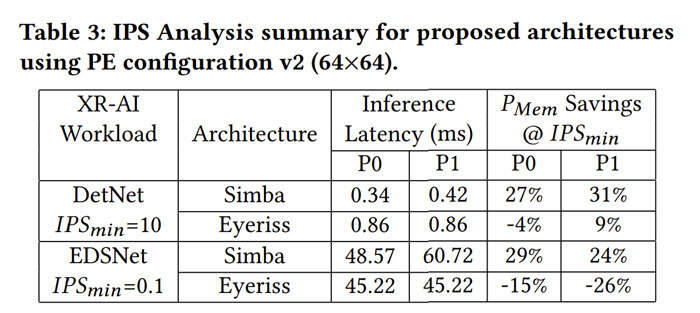
表3总结了所有组合的内存节能关键结果。另外,表3中显示的推断延迟结果反映出Simba提供了利用睡眠时间间隔的最佳机会。
团队假设使用相应的内存技术支持多周期读写操作。这里需要注意的一点是,在7nm时,所考虑的所有存储器技术都具有非常低的读写延迟(≤5ns),相当于SRAM,因此导致操作以与SRAM-only情况类似的推理延迟运行。在这里,他们设置了最小合理的推理吞吐量值(𝐼𝑃𝑆𝑚𝑖𝑛) 分别用于手部检测和眼睛分割应用,分别为~40和~6。
可以总结出,对于缩放节点(7nm),当以较低的推理速率操作时,P1变体在存储器功率节省以及面积方面优于P0和SRAM-only变体。但在读密集型工作负载(如EDSNet)大量使用输入缓冲区的情况下,这种趋势会发生逆转。
P1变体同样会导致略高的推理延迟(≈20%)。然而,这与应用程序无关,因为P1变体的延迟可以很好地满足应用程序对真实世界用例的最低IPS要求。
根据工作负载的性质和应用程序的IPS要求,用NVM完全替换板载易失性存储器可能不是最佳选择,因为NVM写入延迟可能会限制计算速度。另外,考虑到最先进的NVM设备的读写操作的非对称能量耗散趋势,功率效益可能会受到限制。因此,基于工作负载的确切性质(即以存储器读取为主或以存储器写入为主),需要仔细微调NVM和SRAM之间的拆分比例,以获得最佳结果。
结论
总的来说,团队对两种XR-AI工作负载(手部检测和眼睛分割)进行了详细的研究。他们首先给出了网络训练和量化的结果。为了进行更广泛的设计探索,研究人员使用QKeras和Timeloop+Acceptgy框架以及节点缩放分析对CPU和收缩加速器进行了模拟。最后,他们提出了基于使用不同类型的新兴MRAM设备的DTCO。
团队同时分析了在XR计算管道中引入非波动性相对于7nm节点的推断活动率的能量效益。当在存储器层次结构中引入MRAM NVM时,手部检测(在IPS=10时)和眼睛分割(在IPS=0.1时)分别观察到≥24%的存储器能量节省。另外,由于MRAM技术的高密度特性,MRAM取代SRAM可大幅减少面积(≥30%)。
来源:映维网
投稿:tougao@arinchina.com
稿件/商务合作: 向前(微信 Shixiangqian7)电话:18700987744
创始人:张明军(微信 13720775110)
更多精彩内容,请关注ARinChina微信公众号(ID:X增强现实)



评论