
人与人之间的身体交互是日常生活中的重要元素,例如通过握手打招呼,以及一起跳萨尔萨舞。显然,如果能够以可信方式在虚拟角色之间重现这种交互,这将会在游戏、电影或AR/VR等应用中提供一种高度沉浸式体验。
在名为《Simulation and Retargeting of Complex Multi-Character Interactions》的论文中,由佐治亚理工学院,苹果,Meta,卡内基梅隆大学和首尔大学组成的团队就着手进行了研究,并提出了一种使用深度强化学习为物理模拟的人形角色再现复杂多角色交互的方法。
所述方法学习不仅模仿个人动作,而且模仿角色之间的交互,同时保持平衡并匹配参考数据的复杂性的控制策略。他们使用了一种新的基于interaction graph的奖励公式,而它可以测量interaction landmark对之间的距离。这种奖励鼓励控制策略有效地模仿角色的动作,同时保留参考动作中交互的空间关系。团队在各种活动中评估了所提出的方法,包括击掌问候,跳萨尔萨舞和搬箱子等。实验表明,它能够产生物理上合理的交互。
在论文中,研究人员对将复杂的多角色交互从参考运动转移到物理模拟角色感兴趣。这种角色需要在空间和时间领域内仔细协调。对于业界,对物理模拟角色之间交互的研究远远少于对单个角色的研究,部分原因是为多个角色之间的交互学习控制器非常具有挑战性。
与单个角色一样,你必须保持平衡,但交互约束必须同时解决。尽管社区已经出现了一定的突破,但所展示的交互的复杂性依然与人们日常生活中的常规操作相去甚远。
对于佐治亚理工学院,苹果,Meta,卡内基梅隆大学和首尔大学组成的团队,他们展示了一种新的基于学习的方法,并为多个角色的复杂交互提供了一种基于物理学的重定向。更具体地说,给定捕获交互的参考动作,他们通过不仅模仿个体运动,而且模仿他们之间交互的深度强化学习来学习模拟角色的控制策略(又称控制器)。
当角色的大小和运动学存在较大变化时,学习到的策略可以产生可信的和语义上等同的交互。如果模拟角色的大小与原始运动捕获数据中的角色相匹配,产生的运动与参考数据则几乎没有区别,并且通过确保现在的交互在物理上可信,可以消除捕获过程中的任何错误。
为了解决学习多角色交互的挑战,团队开发了基于interaction graph(IG)的新奖励,它测量角色指定位置对之间的距离,特别是反映角色之间的距离。基于IG的奖励令控制策略能够为物理模拟角色有效地部署复杂的交互,同时保留参考数据中包含的交互语义(即空间关系)。

研究人员目标是建立令物理模拟角色能够相互进行复杂的物理交互的控制器。对于每一种行为,他们都会采用代表所需的多角色交互的参考动作捕获片段,并制作允许模拟角色能够模仿相关交互的控制器。
他们希望产生与参考动作中存在的语义相似的角色交互。为了实现这一目标,团队使用了多代理深度强化学习。与其他方法不同的是,这一方案可以应用于动态角色。
对于环境,角色建模为铰接式刚体物体。每个角色有22个链接和22个关节,每个关节有三个自由度,并由给定目标关节角度的稳定PD伺服系统进行驱动。他们使用一个开源的框架来实现和模拟角色。
研究人员将问题表述为一个多代理的马尔可夫决策过程(MDP)。考虑到𝑘个可控制的代理,他们定义了元组{𝑆,𝑂1 – -𝑂𝑘, 𝐴1 – -𝐴𝑘, 𝑅1 – -𝑅𝑘 ,𝑇 、 𝜌}。其中𝑆是环境的整个状态,𝑂𝑖和𝐴𝑖分别是第l个代理的观察和行动。奖励函数𝑅𝑖 : 𝑂𝑖 ×𝐴𝑖 → R评价当前状态和𝑖-th代理的行动的质量,环境由过渡函数𝑇: 𝑆 ×𝐴1×- -×𝐴𝑘 → 𝑆更新,𝜌 : 𝑆 → [0, 1] 则是初始状态的概率分布。
团队的目标是学习一组最优控制策略{𝜋𝑖 |𝑖 = 1 – – 𝑘},为每个代理最大化平均预期收益E Í𝑇 𝑡=0 𝛾 𝑡 𝑟𝑖,𝑡。
为了更好地描述运动过程中代理之间发生的交互的语义,团队定义了IG的概念,这是一个graph-based的空间描述符,交互的信息存储在其顶点和边上。为了构建一个IG,首先在每个角色的突出位置放置了一系列标记(见图2)。每个角色总共有15个标记,其中三个标记在每个肢体的关节位置附近,一个在骨盆,一个在躯干,一个在头部。
标记视为graph的节点,每个节点都与一个六维向量𝑛𝑖 = (𝑝𝑖 , 𝑣𝑖) ∈ R 6,其中𝑝𝑖∈ R 3是顶点的位置,𝑣𝑖∈ R 3是顶点的速度。例如,总共有30个顶点将用于与两个角色相关的交互(见图2)。
在每个时间步长上,根据成对标记之间的空间距离对所有顶点进行Delauney四面体化,得到连接顶点的紧凑的边的集合。每条边都分配一个特征向量𝑒𝑖𝑗=(𝑝𝑖𝑗,𝑣𝑖𝑗)∈R 6,编码两个顶点之间的相对关系、 其中𝑝𝑖𝑗 = 𝑝𝑗 – 𝑝𝑖 ∈R 3,𝑣𝑖𝑗 = 𝑣 – 𝑣𝑖∈R 3是边缘特征的位置和速度成分。
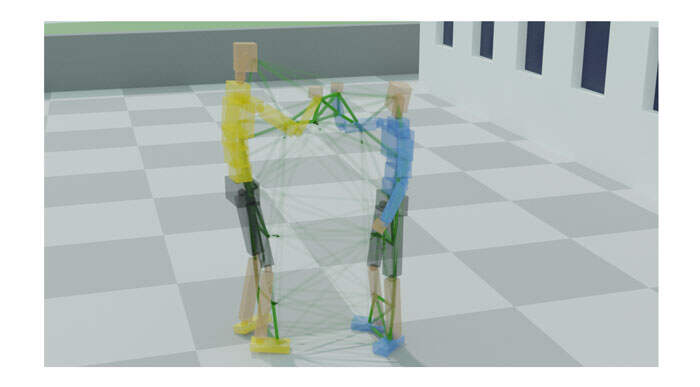
图2中的IG示例既包括连接单个角色上的节点的边,同时包括连接不同角色上的节点的边。角色内部的边有助于保持单个角色的运动质量,而角色之间的边则是保持两个角色的身体部位的相对位置的导向。
团队主要进行边缘级(即距离)的计算,并进一步用速度来增强边缘的状态,因为它们对物理模拟至关重要。考虑到输入的参考运动片段,他们建立并存储这样一个IG以捕获每个时间步的代理和物体的空间关系。
至于奖励设计,研究人员选择用两种方式来衡量交互的相似性:一种是强调graph中交互区域重要性的边缘加权函数,另一种是衡量具有相同连通性的两个IG之间相似性的边缘相似度函数。对于相似性测量,利用两个具有相同连通性的IG:𝐺 𝑠𝑖𝑚和𝐺 𝑟𝑒 𝑓,一个来自模拟环境,另一个来自参考运动剪辑。
实验表明,所述方法足够稳健,可以应用于有多个角色和物体的各种运动。动态调整的权重将运动的调整集中在物理交互。在具有复杂交互的场景中,这种方法的运动质量则比现有方法高。另外,当角色的身体尺寸、运动学和骨架与参考运动序列不同时,所述方案依然能够保持交互。
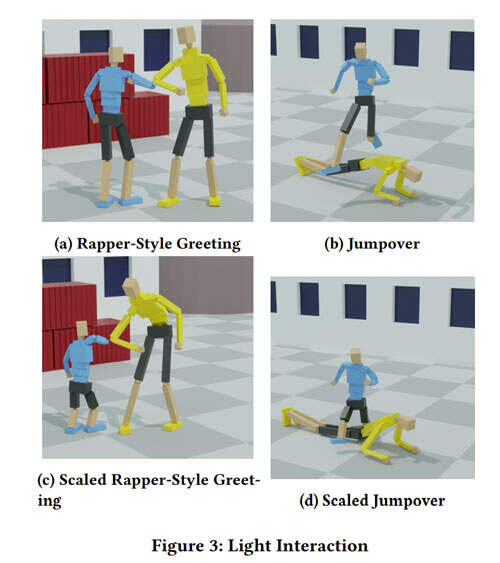


如上面的图示,团队在各种活动中评估了所提出的方法,包括问候和搬箱子等。实验表明,它能够产生物理上合理的交互。

值得一提的是,所述方法同时可以将参考动作中的动作转移到具有不同运动学配置的角色上。例如,如果机器人的自由度比参考角色少,团队提出的方法依然可以支持机器人模仿参考动作中存在的交互。如图4所示,研究人员用一个由两个工业机械手组成的Baxter机器人取代其中一个角色。
由于机器人有一个固定的底座,他们将机器人放置在进行打招呼动作的位置,并在机器人上半身的头部、躯干、上臂、下臂和末端致动器放置了8个标记,以匹配人类角色的标记。对于人类角色,在人体上保持与前面所述相同的15个标记。然后使用总共23个标记来构建训练用的IG。在训练过程中,对角色和机器人独立使用两个单独的奖励函数。
消融研究显示了所述方法在再现物理模拟角色的复杂交互方面的有效性。

图7显示了打招呼动作的比较。对于使用joint-based的奖励训练的控制策略,其未能使高个子的角色弯下腰来并与矮个子角色交互。对于只使用基于关节的奖励训练的控制策略,在其他动作中同样观察到类似的行为。
但与之相比,IG奖励的策略则可以令高个子角色弯下腰来,并与矮个子角色交互。
图8进一步比较了两种方案。当使用IG奖励时,高个子角色主动向前弯腰,将手伸向矮个子角色的小腿,以形成抓取约束并举起矮个子角色。另一方面,当使用Joint-Based奖励时,没有基于两个角色之间的相对姿势的奖励,高个子角色不能抓住矮个子角色的腿,交互语义没有被保留。另外,在为人与物交互重新确定运动目标时,Joint-Based奖励同样会产生较低质量的运动。
总的来说,团队展示了一种通过使用深度强化学习来模拟和重新定位复杂多角色交互的方法,其中新的状态和奖励是基于IG开发,与角色无关。所述方案适用于人与人之间的各种交互,甚至能够转移到机器人,以产生人与机器人的交互。
当然,尽管他们展示了一系列成功的例子,但方法存在一定的局限性。首先,奖励函数设计存在一些限制。因为行动空间与奖励函数没有直接联系。与Joint-Based的奖励函数相比,团队的训练通常需要更多的样本来收敛。另外,由于缺乏对关节角度的监督,从策略中产生的运动可能包含对交互影响不大的关节伪影。例如,有时角色可能会以不自然的角度倾斜头部或腰部,因为这种与参照物的偏差不会影响IG的节点位置,因此它不会减少奖励。添加更多的标记将是一个直接的补救措施,但这会增加计算成本。
另一个限制是,控制器依然是模仿性的控制器,不能执行参考运动中不存在的交互。同时,控制器只对它所训练的特定身体结构起作用,所以一个策略不容易泛化到具有不同身体结构的角色身上。研究人员进一步注意到,结果的可变性受到角色的不相似性和任务难度的限制。由于物理上的限制,比例极大或身体结构截然不同的角色可能无法模仿交互。例如,在具有挑战性的交互场景中,所述方法只能对角色进行轻微的缩放,但当用机器人取代一个人类角色与另一个人类角色执行任务时,就会失败。
未来,团队将继续进行研究和优化。但研究人员表示:“我们相信,我们的方法已经令模拟角色产生复杂的多角色交互成为可能,并将作为未来研究的基础。”
来源:映维网
投稿:tougao@arinchina.com
稿件/商务合作: 向前(微信 Shixiangqian7)电话:18700987744
创始人:张明军(微信 13720775110)
更多精彩内容,请关注ARinChina微信公众号(ID:X增强现实)



评论