
Meta的Unreal fork日前集成了高通的离线编译器Adreno Offline Compiler(AOC)。在下面这篇博文中,团队介绍了如何利用AOC来分析和优化材质着色器性能。

1. 背景
在AOC被整合之前,Unreal开发者并没有一种离线改进Meta Quest材质着色器的快速迭代方法。作为解决方案,他们一般使用两种常见方法:
- Unreal引擎中的Shader Stats:Meta Quest头显采用Adreno GPU,但这个工具仅适用于Mali GPU。唯一可用的统计是指令计数,这并不能很好地显示真正的着色器性能,因为不同类型的指令可能执行不同。例如,在ALU指令和内存访问指令之间存在很大的性能差异。
- RenderDoc中的Shader Stats:为了获得更准确的着色器性能统计数据,Quest开发者使用RenderDoc来收集在线统计数据,但这种方法需要RenderDoc的专业知识,从而可能会增加开发时间。另外,所述方法的材质迭代缓慢:在GPU启动样本需要时间,并且RenderDoc统计只能从在线GPU检索。
随着AOC的发布,Quest开发者现在可以访问丰富的着色器统计数据,并以最小的努力离线收集它们,从而大大缩短了材质迭代时间。
2. AOC介绍
如上图所示,AOC直接在UE5材质编辑器中为不同的着色器提供丰富的着色器统计。另外,AOC支持各种命令行选项,包括GPU arch targets,view mask和graphics APIs等,这为开发者和游戏引擎提供了更大的灵活性。注意:与二进制文件一起安装的OfflineCompiler.html详细解释了所有AOC统计信息。
AOC现在已经很好地集成到Unreal引擎的着色器统计窗口中,开发者可以轻松访问和导出所有着色器统计。
请注意,Meta建议使通过改变材质属性来检查材质性能趋势,然后检查着色器状态的变化。不建议使用AOC来比较材质的性能,因为材质可能会存在很大的不同。例如,一种材质有Flow控制和许多内存访问,而另一种材质有很高的寄存器压力。在这种情况下,使用AOC来估计性能差异非常具有挑战性。
3. 入门:设置你的环境
为了更好地演示AOC的有效性,下面将讨论几个用例。其中,示例改变了特定材质的属性,然后通过使用AOC的着色器统计、RenderDoc的着色器统计和实时应用时间来检查性能趋势。按照下面的链接设置您的环境(所有用例都使用UE5,AOC1.3和Meta Quest 2运行):
- AOC:按照这个文档设置AOC和材质状态
- RenderDoc Shader Stats:按照这个文档获取RenderDoc Shader Stats
- 实时GPU测量:按照这个链接设置GPU实时测量
注意:示例使用AOC1.3,因为RenderDoc使用相同的统计数据,使得比较两个工具之间的结果更容易。对于GPU实时测量(示例输出如下),只使用每个用例的App时间。
04-16 23:21:46.004 475 2186 I VrApi : FPS=72/72,Prd=29ms,Tear=0,Early=0,Stale1/2/5/10/max=0/0/0/0/0,VSnc=0,Lat=-1,Fov=0D,CPU4/GPU=4/3,1478/490MHz,OC=FF,TA=0/0/0,SP=N/N/N,Mem=2092MHz,Free=3030MB,PLS=0,Temp=33.7C/0.0C,TW=0.00ms,App=3.86ms,GD=0.00ms,CPU&GPU=10.07ms,LCnt=1(DR0,LM0),GPU%=0.28,CPU%=0.28(W0.32),DSF=1.00,CFL=19.79/21.58
4. 用例
下面的四个用例演示了如何使用AOC来分析和优化材质着色器的性能。
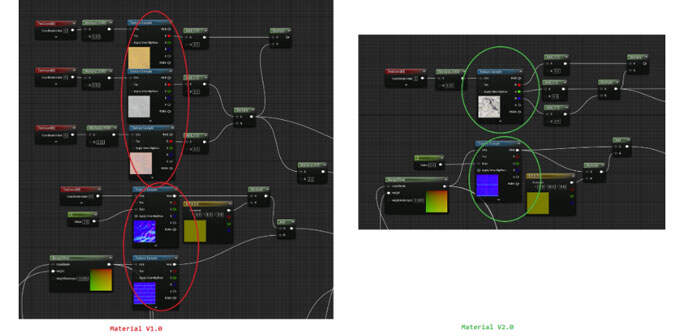
- 减少纹理操作:下图显示Material v2.0中的一个纹理操作取代了Material v1.0中的三个纹理操作,另外两个纹理操作同时由一个纹理操作所取代。
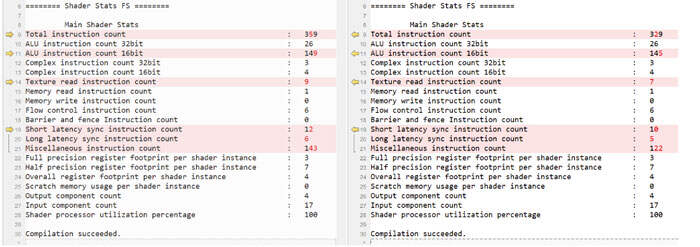
- AOC Shader Stats Delta:下面的着色器统计来自AOC,左边是Material v1.0,右边是2.0版本。“Texture read instruction count/纹理读取指令计数”和“Long latency sync instruction count/长延迟同步指令计数”都减少了,这表明性能有所提高。注意:诸如ALU等其他统计数据同样发生了变化,但不太可能显著影响性能。
- 验证
- 应用时间:应用时间从v1.0的4.04ms降低到v2.0的3.86ms,确认AOC的统计趋势是正确的。
- RenderDoc Shader Stats Delta:下面RenderDoc的统计显示了与AOC相似的趋势。请注意,每个stat的绝对值在RenderDoc和AOC之间可能不同。例如,RenderDoc的“Instruction count all”是375,而AOC的是359。
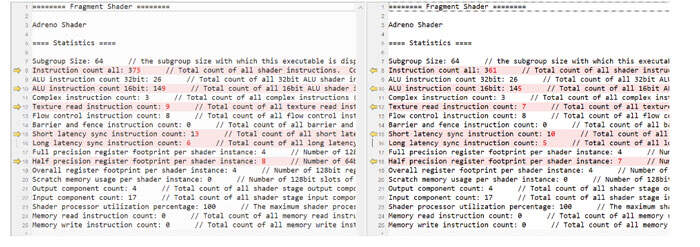
- 改变精度:下面的结果是通过创建一个基于M_Water_Ocean_Math的材质,然后将其精度更改为全精度来生成。左边为原材质,右边为全精度。结果,32位ALU指令数增加了很多,16位ALU指令数减少了很多。其他统计数据,如复杂指令、寄存器占用和着色器处理器利用率百分比同样有相同的趋势(更糟糕的性能)。
- 验证
- 应用时间:应用时间从常规精度的4.8ms增加到全精度的5.95ms,确认AOC的统计趋势是正确的。
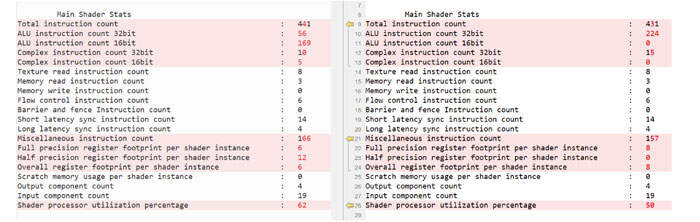
- RenderDoc Shader Stats Delta:RenderDoc的统计数据显示了与AOC相似的趋势。
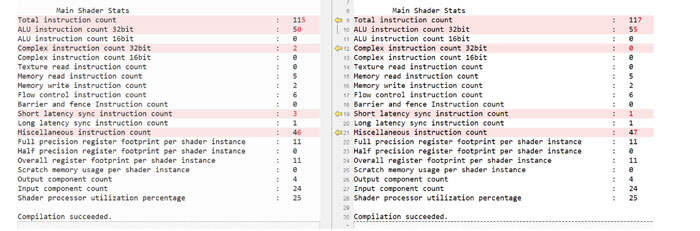
- 用简单的数学运算替换复杂的数学运算:在下图中,用简单的数学运算替换了VertexShader中复杂的数学运算。

- AOC Shader Stats Delta:复杂指令计数减少,ALU指令增加。考虑到ALU指令通常比复杂指令低成本,Meta对性能的提高相对有信心。
- 验证
- 应用时间:应用时间从v1.0的4.41ms减少到v2.0的4.38ms,确认AOC的统计趋势是正确的。
- RenderDoc Shader Stats Delta:RenderDoc的统计显示了与AOC相似的趋势。请注意,下面的示例在AOC中没有任何诸如“ALU指令计数32位”之类的Noise,并且下面的所有统计数据都显示性能有所提高。这表明有时候AOC和在线GPU对于特定统计趋势可能会有所不同。
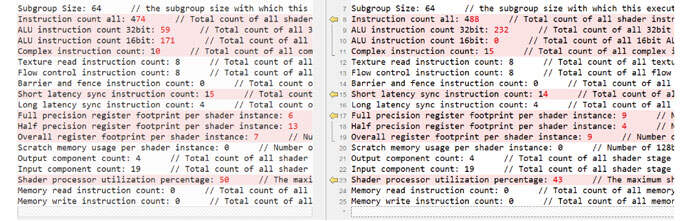
- 用Voronoi替换Simplex Noise Function:在下图中,用Voronoi替换了材质的Simplex Noise Function。

- AOC Shader Stats Delta:“总指令计数”和“纹理读取指令计数”显著减少,寄存器占用同样减少。然而,我们得到了更高的“Flow控制指令计数”。这意味着几乎不可能将这种额外branch的性能损失与纹理指令的性能收益进行比较。这同时意味着基于所述统计比较,我们不应该得出性能趋势的结论。相反,我们应该收集实时性能数据,从而确定性能趋势。注意,如果打开生成的SPIR-V指令,我们将看到branch主要来自特定循环branch。如果一个着色器比另一个着色器多一个循环,性能可能会有很大的不同。

- 验证
- 应用时间:应用时间从Simplex Noise的26.8ms增加到Voronoi Noise的124ms,证实我们不应该根据AOC的结果来估计性能趋势。
- RenderDoc Shader Stats Delta:下面RenderDoc的统计显示了非常不同的结果,特别是“总指令计数”。主要原因可能与在线GPU编译器和离线GPU编译器之间的branch优化差异有关,因为离线GPU编译器缺乏与循环相关的情景信息。如下图所示,唯一的性能损失来自于Flow控制,并且它在上述应用时间内是巨大的。
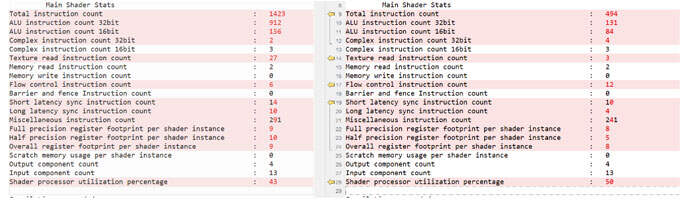
对于上面的所有用例,我们将重点放在AOC和RenderDoc之间的公共统计数据上,以显示AOC有效性的1对比比较。但即便对于常见的统计数据,AOC和RenderDoc的绝对值都可能不同,因为在线GPU编译器可以动态地处理其他驱动程序数据,并且比离线AOC执行更多的优化。
AOC限制
上面的用例演示了如何使用AOC更好地理解和优化应用程序。没有一个单一的统计数据可以告诉你材质性能趋势是好是坏。相反,你可以根据你独特的应用程序对不同的材质使用不同的着色器统计数据。
从high-level角度来看,并行性和内存访问是影响着色器性能的两个关键因素。寄存器压力会严重影响并行性,而内存访问如果隐藏不好则会带来严重的延迟。这就是为什么“register footprint”、“ALU fiber occupancy percentage”、以及任何与内存相关的统计(包括纹理)通常都很有趣的原因。
另一方面,如果材质使用了复杂的指令或者使用了Flow控制,这可能会对性能造成不利影响,而你可能需要关注“复杂指令计数”和“Flow控制指令计数”。通常,ALU指令非常快,这就是为什么要注意“总指令数”的原因之一,因为它可能会产生误导。较高的“总指令计数”并不一定表示性能较差,详细查看其他统计数据将有助于了解进一步的性能趋势。
Unreal引擎集成状态
Unreal引擎的框架不支持离线编译整个着色器管道(VS+FS)。所以,当AOC集成到Unreal引擎中时,Meta总是使用AOC单独编译每个着色器,VS或FS,并且假设没有通过编译整个着色器管道来极大地优化着色器的情况。团队同时假设只有VS和FS(没有其他着色器类型)。
目前,这个集成只支持Meta的Unreal fork。团队正在与Epic合作,以将这个功能带到Unreal fork。
Meta总结道:“我们相信AOC是一个强大的工具,可以帮助你分析和优化材质着色器的性能。由于它能够离线运行,AOC可以帮助你大大减少材质迭代时间。”
来源:映维网
投稿:tougao@arinchina.com
稿件/商务合作: 向前(微信 Shixiangqian7)电话:18700987744
创始人:张明军(微信 13720775110)
更多精彩内容,请关注ARinChina微信公众号(ID:X增强现实)



评论